First published: 2024-01-26
Last updated: 2024-01-29
About the Mesh Shading Series
This post is part 3 of a series about mesh shading. My intent in this series is to introduce the various parts of mesh shading in an easy to understand fashion. Well, as easy as I can make it. My objective isn’t to convince you to use mesh shading. I assume you’re reading this post because you’re already interested in mesh shading. Instead, my objective is to explain the mechanics of how to do mesh shading in Direct3D 12, Metal, and Vulkan as best I can. My hope is that you’re able to use this information in your own graphics projects and experiments.
- Mesh Shading Part 1: Rendering Meshlets
- Mesh Shading Part 2: Amplification
- Mesh Shading Part 3: Instancing
- Mesh Shading Part 4: Culling
- Mesh Shading Part 5: LOD Selection
- Mesh Shading Part 6: LOD Calculation
- Mesh Shading Part 7: Culling + LOD
- Mesh Shading Part 8: Vertex Attributes (TBD)
- Mesh Shading Part 9: Barycentric Interpolation (TBD)
Sample Projects for This Post
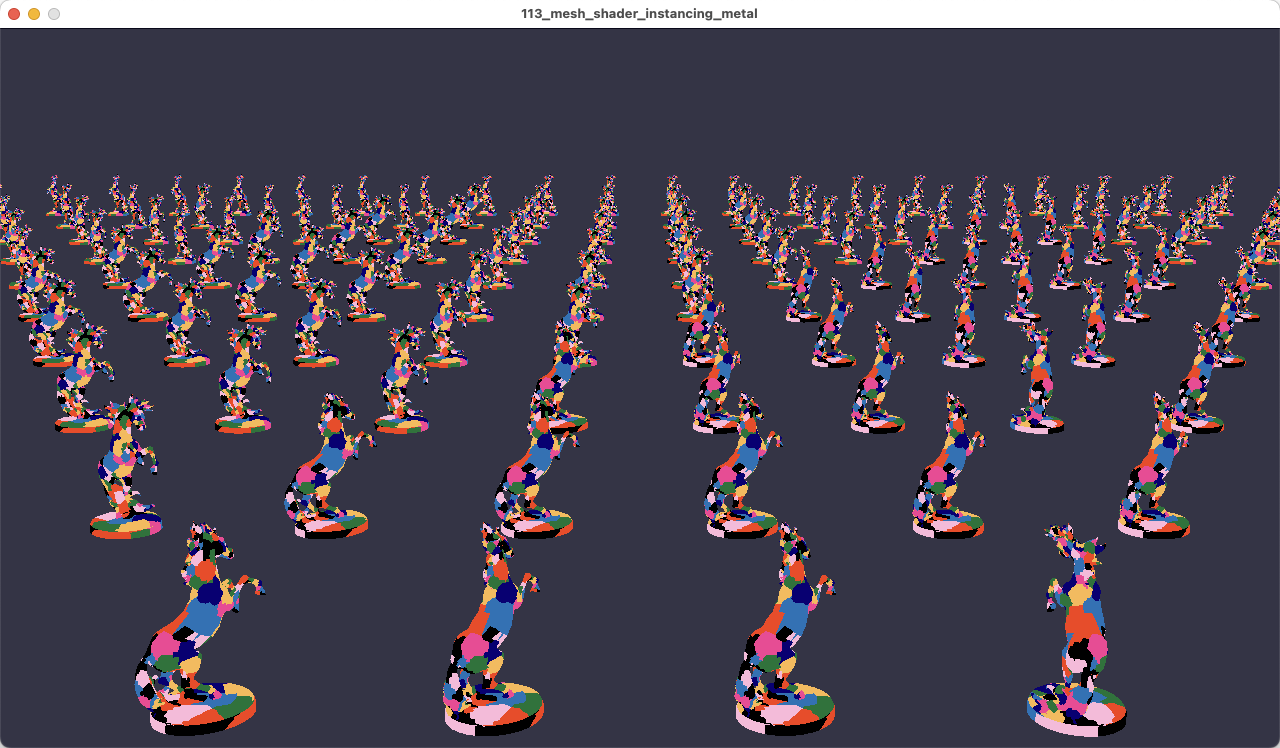
113_mesh_shader_instancing - Demonstrates how to do instancing using amplification. Renders the same model’s meshlets in many different locations.
The D3D12 version of 113_mesh_shader_instancing displays pipeline statistics. The Metal and Vulkan versions do not display pipeline statistics for different reasons. Metal doesn’t have pipeline statistics. Turning on pipeline statistics on the Vulkan version tanks the performance. I haven’t had a chance to investigate why this is and how it affects the various GPUs.
Introduction
Originally, amplification and instancing were planned for the same post. But as I writing it, I saw that the post started to get pretty long. So I decided to split the topics into two posts. This post is an immediate follow up to Mesh Shading Part 2: Amplification.
Just a heads up, this post is pretty code heavy since we’re just going over the necessary changes to instance. But even though there’s a bit of code, it should be a relatively short read.
A Note About Instancing In This Post
We’re covering basic instancing in this post which goes over object instancing. We will not do anything clever like D3D12 Meshlet Instancing Sample. The intent is to get you familiar with how to instance using amplification. Perhaps a later post will breakdown what’s happening in the D3D12 sample.
C++ Changes
I’m going to cover the changes in C++ one way and the shader code another. The C++ code is scatted throughout the file so it’s not practical to paste a giant chunk of code. The shader code is much smaller so having a chunk of code is less punishing to someone reading this.
Here’s a list of noteable changes in the C++ code:
- Add a buffer to store a 4x4 transform matrix for the instances - this is also known as the model matrix
- Add some code to update transform matrix for each instance for each frame
- Change constant data store a view projection instead of of a model view projection matrix
- Add instance count to constant data
- Change how constant data and descriptors are updated/set
- Change threadgroup count for dispatch calls
Now, we’ll go over the details of these changes in the listed order!
Instances Buffer
const uint32_t kNumInstanceCols = 20;
const uint32_t kNumInstanceRows = 10;
std::vector<mat4> instances(kNumInstanceCols * kNumInstanceRows);
// -----------------------------------------------------------------------------
// Direct3D
// -----------------------------------------------------------------------------
ComPtr<ID3D12Resource> instancesBuffer;
CreateBuffer(renderer.get(), SizeInBytes(instances), D3D12_HEAP_TYPE_UPLOAD, &instancesBuffer);
// -----------------------------------------------------------------------------
// Metal
// -----------------------------------------------------------------------------
MetalBuffer instancesBuffer;
CreateBuffer(renderer.get(), SizeInBytes(instances), nullptr, &instancesBuffer);
// -----------------------------------------------------------------------------
// Vulkan
// -----------------------------------------------------------------------------
VulkanBuffer instancesBuffer;
VkBufferUsageFlags usageFlags = VK_BUFFER_USAGE_STORAGE_BUFFER_BIT;
CreateBuffer(renderer.get(), SizeInBytes(instances), DataPtr(instances), usageFlags, 0, &instancesBuffer);
Our instance data throughout the majority of the posts will be simple: just one 4x4 transform matrix. We need storage on both the CPU and GPU. On the CPU since we’ll be doing CPU side updates to the tranform. And of course the GPU since we’ll need to uplaoded the updated transforms for the rendering code to use.
The code here calls the version of CreateBuffer() that uploads the contents of instances but it’s just random garbage data at this point. We’ll overwrite it immediately in the next section.
Based on the values of kNumInstanceCols and kNumInstanceRows we’re going to draw 200 instances.
Instance Transform Updates
// Update instance transforms
float maxSpan = std::max<float>(meshBounds.Width(), meshBounds.Depth());
float instanceSpanX = 2.0f * maxSpan;
float instanceSpanZ = 4.5f * maxSpan;
float totalSpanX = kNumInstanceCols * instanceSpanX;
float totalSpanZ = kNumInstanceRows * instanceSpanZ;
for (uint32_t j = 0; j < kNumInstanceRows; ++j)
{
for (uint32_t i = 0; i < kNumInstanceCols; ++i)
{
float x = i * instanceSpanX - (totalSpanX / 2.0f) + instanceSpanX / 2.0f;
float y = 0;
float z = j * instanceSpanZ - (totalSpanZ / 2.0f) - 2.15f * instanceSpanZ;
uint32_t index = j * kNumInstanceCols + i;
float t = static_cast<float>(glfwGetTime()) + ((i ^ j + i) / 10.0f);
instances[index] = glm::translate(glm::vec3(x, y, z)) * glm::rotate(t, glm::vec3(0, 1, 0));
}
}
// -----------------------------------------------------------------------------
// Direct3D - map, copy, unmap
// -----------------------------------------------------------------------------
void* pDst = nullptr;
CHECK_CALL(instancesBuffer->Map(0, nullptr, &pDst));
memcpy(pDst, instances.data(), SizeInBytes(instances));
instancesBuffer->Unmap(0, nullptr);
// -----------------------------------------------------------------------------
// Metal - copy, inform GPU of buffer modification
// -----------------------------------------------------------------------------
memcpy(instancesBuffer.Buffer->contents(), DataPtr(instances), SizeInBytes(instances));
instancesBuffer.Buffer->didModifyRange(NS::Range::Make(0, SizeInBytes(instances)));
// -----------------------------------------------------------------------------
// Vulkan - map, copy, unmap
// -----------------------------------------------------------------------------
void* pDst = nullptr;
CHECK_CALL(vmaMapMemory(renderer.get()->Allocator, instancesBuffer.Allocation, reinterpret_cast<void**>(&pDst)));
memcpy(pDst, instances.data(), SizeInBytes(instances));
vmaUnmapMemory(renderer.get()->Allocator, instancesBuffer.Allocation);
We’re layingout the 200 instances of the horse statue in a 20x10 grid of columns by rows. They’ll be spread apart using some spans calculated based on the bounding box of the horse statue. Straightforward and simple.
Each instance is rotated around the Y-axis using the time returned by glfwGetTime() with an offset applied to it. We just need enough variation to break up the unformity.
D3D12 and Vulkan - we do the old map, copy, unmap dance for simplicity.
Metal - we copy and then tell it we wrote some data.
At this point, the instances’ transform matrices are ready to go.
Constant Data Changes
PerspCamera camera = PerspCamera(45.0f, window->GetAspectRatio(), 0.1f, 1000.0f);
camera.LookAt(vec3(0, 0.7f, 3.0f), vec3(0, 0.105f, 0));
mat4 VP = camera.GetViewProjectionMatrix();
uint32_t instanceCount = static_cast<uint32_t>(instances.size());
uint32_t meshletCount = static_cast<uint32_t>(meshlets.size());
The model matrix now resides with each instance, so we for our constant data we only upload a view projetion matrix.
In addition to the meshletCount, we will also be uploading an instanceCount so we know how many instances we have when inside the shader code.
Constant Data and Descriptor Changes
// -----------------------------------------------------------------------------
// Direct3D - Set constant data and descriptors
// -----------------------------------------------------------------------------
commandList->SetGraphicsRoot32BitConstants(0, 16, &VP, 0);
commandList->SetGraphicsRoot32BitConstants(0, 1, &instanceCount, 16);
commandList->SetGraphicsRoot32BitConstants(0, 1, &meshletCount, 17);
commandList->SetGraphicsRootShaderResourceView(1, positionBuffer->GetGPUVirtualAddress());
commandList->SetGraphicsRootShaderResourceView(2, meshletBuffer->GetGPUVirtualAddress());
commandList->SetGraphicsRootShaderResourceView(3, meshletVerticesBuffer->GetGPUVirtualAddress());
commandList->SetGraphicsRootShaderResourceView(4, meshletTrianglesBuffer->GetGPUVirtualAddress());
commandList->SetGraphicsRootShaderResourceView(5, instancesBuffer->GetGPUVirtualAddress());
// -----------------------------------------------------------------------------
// Metal - Set constant data and descriptors
// -----------------------------------------------------------------------------
//
// Use a struct since metalcpp doesn't seem to expose a
// variant of set*Bytes with an offset currently.
//
struct SceneProperties {
mat4 CameraVP;
uint InstanceCount;
uint MeshletCount;
uint pad[2];
};
SceneProperties scene = {VP, instanceCount, meshletCount};
pRenderEncoder->setObjectBytes(&scene, sizeof(SceneProperties), 0);
pRenderEncoder->setMeshBytes(&scene, sizeof(SceneProperties), 0);
pRenderEncoder->setMeshBuffer(positionBuffer.Buffer.get(), 0, 1);
pRenderEncoder->setMeshBuffer(meshletBuffer.Buffer.get(), 0, 2);
pRenderEncoder->setMeshBuffer(meshletVerticesBuffer.Buffer.get(), 0, 3);
pRenderEncoder->setMeshBuffer(meshletTrianglesBuffer.Buffer.get(), 0, 4);
pRenderEncoder->setMeshBuffer(instancesBuffer.Buffer.get(), 0, 5);
// -----------------------------------------------------------------------------
// Vulkan - pPush constant data and descriptors
// -----------------------------------------------------------------------------
vkCmdPushConstants(CommandBuffer, pipelineLayout, VK_SHADER_STAGE_MESH_BIT_EXT | VK_SHADER_STAGE_TASK_BIT_EXT, 0, sizeof(mat4), &VP);
vkCmdPushConstants(CommandBuffer, pipelineLayout, VK_SHADER_STAGE_MESH_BIT_EXT | VK_SHADER_STAGE_TASK_BIT_EXT, sizeof(mat4), sizeof(uint32_t), &instanceCount);
vkCmdPushConstants(CommandBuffer, pipelineLayout, VK_SHADER_STAGE_MESH_BIT_EXT | VK_SHADER_STAGE_TASK_BIT_EXT, sizeof(mat4) + sizeof(uint32_t), sizeof(uint32_t), &meshletCount);
PushGraphicsDescriptor(CommandBuffer, pipelineLayout, 0, 1, VK_DESCRIPTOR_TYPE_STORAGE_BUFFER, &positionBuffer);
PushGraphicsDescriptor(CommandBuffer, pipelineLayout, 0, 2, VK_DESCRIPTOR_TYPE_STORAGE_BUFFER, &meshletBuffer);
PushGraphicsDescriptor(CommandBuffer, pipelineLayout, 0, 3, VK_DESCRIPTOR_TYPE_STORAGE_BUFFER, &meshletVerticesBuffer);
PushGraphicsDescriptor(CommandBuffer, pipelineLayout, 0, 4, VK_DESCRIPTOR_TYPE_STORAGE_BUFFER, &meshletTrianglesBuffer);
PushGraphicsDescriptor(CommandBuffer, pipelineLayout, 0, 5, VK_DESCRIPTOR_TYPE_STORAGE_BUFFER, &instancesBuffer);
D3D12 and Vulkan now has an extra root/push constant for instanceCount.
For Metal, I wasn’t able to find versions of setObjectBytes() and setMeshBytes() that took an offset. It seemed like Metal wants you to just upload everything at once. Which is what I ended up doing. Additionally, I had to add the 2 uints a the end of the struct to align the CPU side struct with the size of the GPU side struct from the shaders.
As a reminder, this code also we upload the instanceCount and the meshletCount values that later become Scene.InstanceCount and Scene.MeshletCount, rspectively.
And lastly, we add a descriptor update for instancesBuffer.
Dispatch Call Changes
// -----------------------------------------------------------------------------
// Direct3D
// -----------------------------------------------------------------------------
// Amplification shader uses 32 for thread group size
UINT meshletCount = static_cast<UINT>(meshlets.size());
UINT instanceCount = static_cast<UINT>(instances.size());
UINT threadGroupCountX = ((meshletCount * instanceCount) / 32) + 1;
commandList->DispatchMesh(threadGroupCountX, 1, 1);
// -----------------------------------------------------------------------------
// Metal
// -----------------------------------------------------------------------------
// Object function uses 32 for thread group size
uint32_t meshletCount = static_cast<uint32_t>(meshlets.size());
uint32_t instanceCount = static_cast<uint32_t>(instances.size());
uint32_t threadGroupCountX = ((meshletCount * instanceCount) / 32) + 1;
pRenderEncoder->drawMeshThreadgroups(MTL::Size(threadGroupCountX, 1, 1), MTL::Size(32, 1, 1), MTL::Size(128, 1, 1));
// -----------------------------------------------------------------------------
// Vulkan
// -----------------------------------------------------------------------------
// Task (amplification) shader uses 32 for thread group size
uint32_t meshletCount = static_cast<uint32_t>(meshlets.size());
uint32_t instanceCount = static_cast<uint32_t>(instances.size());
uint32_t threadGroupCountX = ((meshletCount * instanceCount) / 32) + 1;
vkCmdDrawMeshTasksEXT(CommandBuffer, threadGroupCountX, 1, 1);
We need to update our threadgroup count so that the value is large enough to cover each of our 200 instances.
Lets make sure the math checks out and we have enough amplification threadgroups to cover the 241*200=48200 total meshlets.
meshletCount = meshlets.size();
instanceCount = instances.size();
threadGroupCountX = ((meshletCount * instanceCount) / 32) + 1;
meshletCount = 241;
instanceCount = 200;
threadGroupCountX = ((241 * 200) / 32) + 1;
threadGroupCountX = (48200/ 32) + 1;
threadGroupCountX = (48200/ 32) + 1;
threadGroupCountX = 1506 + 1;
threadGroupCountX = 1507;
1507*32=48224 threads sufficiently covers the 48200 total meshlets with 24 threads that won’t process anything.
Amplification Shader Changes
Here are the mostly complete amplification shaders. We’ll cover the changes in detail immediately after the code blocks.
HLSL for D3D12 and Vulkan
#define AS_GROUP_SIZE 32
struct SceneProperties {
float4x4 CameraVP;
uint InstanceCount;
uint MeshletCount;
};
DEFINE_AS_PUSH_CONSTANT
ConstantBuffer<SceneProperties> Scene : register(b0);
struct Payload {
uint InstanceIndices[AS_GROUP_SIZE];
uint MeshletIndices[AS_GROUP_SIZE];
};
groupshared Payload sPayload;
[numthreads(AS_GROUP_SIZE, 1, 1)]
void asmain(
uint gtid : SV_GroupThreadID,
uint dtid : SV_DispatchThreadID,
uint gid : SV_GroupID
)
{
bool visible = false;
uint instanceIndex = dtid / Scene.MeshletCount;
uint meshletIndex = dtid % Scene.MeshletCount;
if ((instanceIndex < Scene.InstanceCount) && (meshletIndex < Scene.MeshletCount)) {
visible = true;
sPayload.InstanceIndices[gtid] = instanceIndex;
sPayload.MeshletIndices[gtid] = meshletIndex;
}
uint visibleCount = WaveActiveCountBits(visible);
DispatchMesh(visibleCount, 1, 1, sPayload);
}
MSL for Metal
struct SceneProperties {
float4x4 CameraVP;
uint InstanceCount;
uint MeshletCount;
};
struct Payload {
uint InstanceIndices[AS_GROUP_SIZE];
uint MeshletIndices[AS_GROUP_SIZE];
};
[[object]]
void objectMain(
constant SceneProperties& Scene [[buffer(0)]],
uint gtid [[thread_position_in_threadgroup]],
uint dtid [[thread_position_in_grid]],
object_data Payload& outPayload [[payload]],
mesh_grid_properties outGrid)
{
uint visible = 0;
uint instanceIndex = dtid / Scene.MeshletCount;
uint meshletIndex = dtid % Scene.MeshletCount;
if ((instanceIndex < Scene.InstanceCount) && (meshletIndex < Scene.MeshletCount)) {
visible = 1;
outPayload.InstanceIndices[gtid] = instanceIndex;
outPayload.MeshletIndices[gtid] = meshletIndex;
}
// Assumes all meshlets are visible
uint visibleCount = simd_sum(visible);
outGrid.set_threadgroups_per_grid(uint3(visibleCount, 1, 1));
}
Notable Changes
SceneProperties replaced CameraProperties
struct SceneProperties {
float4x4 CameraVP;
uint InstanceCount;
uint MeshletCount;
};
// -----------------------------------------------------------------------------
// HLSL
// -----------------------------------------------------------------------------
DEFINE_AS_PUSH_CONSTANT
ConstantBuffer<SceneProperties> Scene : register(b0);
// -----------------------------------------------------------------------------
// MSL
// -----------------------------------------------------------------------------
constant SceneProperties& Scene [[buffer(0)]]
We upgraded our constant data stucture from just a camera to a scene! It’s not a very detailed scene, but at least now it’s generic enough for us to have other variables in it, such as the new InstanceCount. We’ll see what this is used for shortly.
Payload Changes
struct Payload {
uint InstanceIndices[AS_GROUP_SIZE];
uint MeshletIndices[AS_GROUP_SIZE];
};
Payload now also includes an array for InstancesIndices. We’ll use this soon to look up which model matrix to use for rendering.
Instance and Meshlet Indices Calculation
uint instanceIndex = dtid / Scene.MeshletCount;
uint meshletIndex = dtid % Scene.MeshletCount;
This is the bit of math inside the amplification shader that works out which instance and which meshlet within that instance we’re looking at.
It should be relatively straightforward, but if it’s not, then here’s some worked out math examples. Earlier, we said that we have a total of 48224 threads. This means that dtid will range from 0 to 48223. Our MeshletCount remains the same at 241.
dtid = 240
instanceIndex = 240 / 241 = 0;
meshletIndex = 240 % 241 = 240;
// Looking at last meshlet of instance 0
dtid = 1024
instanceIndex = 1024 / 241 = 4;
meshletIndex = 1024 % 241 = 61;
// Looking at meshle 60 of instance 4
dtid = 48223
instanceIndex = 48223 / 241 = 200;
meshletIndex = 48223 % 241 = 23;
// Out of range since instanceIndex=200 exceeds the 0 to 199 instance indices of our 200 horse statue instances
So the division and modulo expressions above will let us workout which instanceIndex and which meshletIndex our thread with a specific dtid is looking at.
Instance Visibility and Wave Sizes
HLSL for Direct3D and Vulkan
bool visible = false;
uint instanceIndex = dtid / Scene.MeshletCount;
uint meshletIndex = dtid % Scene.MeshletCount;
if ((instanceIndex < Scene.InstanceCount) && (meshletIndex < Scene.MeshletCount)) {
visible = true;
sPayload.InstanceIndices[gtid] = instanceIndex;
sPayload.MeshletIndices[gtid] = meshletIndex;
}
uint visibleCount = WaveActiveCountBits(visible);
DispatchMesh(visibleCount, 1, 1, sPayload);
MSL for Metal
uint visible = 0;
uint instanceIndex = dtid / Scene.MeshletCount;
uint meshletIndex = dtid % Scene.MeshletCount;
if ((instanceIndex < Scene.InstanceCount) && (meshletIndex < Scene.MeshletCount)) {
visible = 1;
outPayload.InstanceIndices[gtid] = instanceIndex;
outPayload.MeshletIndices[gtid] = meshletIndex;
}
// Assumes all meshlets are visible
uint visibleCount = simd_sum(visible);
outGrid.set_threadgroups_per_grid(uint3(visibleCount, 1, 1));
When we get to culling, visible will have a fuller definition. In this post however, visible simply means: does the dtid workout to values of instanceIndex and meshletIndex that are within the valid range. Valid range meaning are they under the Scene.InstanceCount and Scene.MeshletCout, respectively.
Remember, we uploaded instanceCount and meshletCount, from the CPU via the constant data, to become Scene.InstanceCount and Scene.MeshletCount.
Determine Visibility
Here’s how we determine visibility:
- We start out assuming that meshlet is not visible, i.e.
visibleisfalseor0depending on the API. - Calculate
instanceIndexandmeshletIndexfrom dtid - If
instanceIndexandmeshletIndexare within the valid range, then setvisibletotrueor1depending on the API.
Payload Writes
If we’re visible, go ahead and also write the instanceIndex and meshletIndex to the payload.
Wave Intrinsics
If you’re not familiar with Wave Intrinsics this will be the lightest possible introduction.
The wave intrinsic WaveActiveCountBits() and simd_sum helps us determine how many mesh shader threadgroups we need to launch. Both of these are wave level functions, meaning they operate across the entire wave. What WaveActiveCountBits() and simd_sum do is sums up the values of the variable passed into it across the entire wave and then returns that sum to every thread (or lane) in the wave.
For our specific case here, we’re going to sum the values of visible across all the threads of a wave. In our shader, visible can only be 1 or 0. If visible is true or 1 it contributes 1 to the total sum of these functions, otherwise 0.
NOTE: The reason why the above paragraph calls out visible being true or 1 is due the difference in parameter types of WaveActiveCountBits() and simd_sum.
WaveActiveCountBits() takes a bool parameter, whereas simd_sum() accepts a uint but not a bool. The MSL Spec says that simd_sum()’s parameter is a scalar type and also has bool in its list of scalar types. However, the runtime disagrees with the usage of simd_sum() and a bool argument.
So what is the sum if all the threads in the wave contributes 1? That would be 32. Why 32? 32 is the number of threads in a GPU wave, aka the GPU’s wave size. We had briefly mentioned GPU wave sizes in Mesh Shading Part 2: Amplification. NVIDIA calls waves warps. Apple calls waves SIMD groups. It’s all the same thing.
The above is why we selected AS_GROUP_SIZE to be 32.
Does AS_GROUP_SIZE need to be 32?
No, it does not need to be 32. Since we’re using dtid to determine instanceIndex and meshletIndex, the logic will still workout even if AS_GROUP_SIZE doesn’t line up with the GPU’s wave size. One could make the argument that for a real world application, lining up with the GPU’s wave size may be beneficial.
GPU Wave Sizes
We know the wave size for NVIDIA because it’s pretty well documented, see Wikipedia Ampere (microarchitecture) and Turing Tuning Guide for CUDA.
We know the wave size for Apple because, well #google. For Apple Silicon, threadExecutionWidth returns 32.
AMD supports wave sizes of 32 and 64 starting with RDNA according to RDNA (microarchitecture). Wave32 (aka wave size of 32) is the native size according to OPTIMIZING FOR THE RADEON RDNA ARCHITECTURE.
Intel supports wave sizes of 8, 16, and 32 according to Intel® Arc™ A-series Graphics Gaming API Developer and Optimization Guide. Wave size selection is based on driver level shader compiler heuristics according to the linked document.
Mesh Shader Changes
Here are the mostly complete mesh shaders. We’ll cover the changes in detail immediately after the code blocks.
HLSL for D3D12 and Vulkan
struct SceneProperties {
float4x4 CameraVP;
uint InstanceCount;
uint MeshletCount;
};
DEFINE_AS_PUSH_CONSTANT
ConstantBuffer<SceneProperties> Scene : register(b0);
struct Instance
{
float4x4 M;
};
// ...other buffers
StructuredBuffer<Instance> Instances : register(t5);
struct Payload {
uint InstanceIndices[AS_GROUP_SIZE];
uint MeshletIndices[AS_GROUP_SIZE];
};
[outputtopology("triangle")]
[numthreads(128, 1, 1)]
void msmain(
uint gtid : SV_GroupThreadID,
uint gid : SV_GroupID,
in payload Payload payload,
out indices uint3 triangles[128],
out vertices MeshOutput vertices[64])
{
uint instanceIndex = payload.InstanceIndices[gid];
uint meshletIndex = payload.MeshletIndices[gid];
Meshlet m = Meshlets[meshletIndex];
SetMeshOutputCounts(m.VertexCount, m.TriangleCount);
if (gtid < m.TriangleCount) {
//
// meshopt stores the triangle offset in bytes since it stores the
// triangle indices as 3 consecutive bytes.
//
// Since we repacked those 3 bytes to a 32-bit uint, our offset is now
// aligned to 4 and we can easily grab it as a uint without any
// additional offset math.
//
uint packed = TriangleIndices[m.TriangleOffset + gtid];
uint vIdx0 = (packed >> 0) & 0xFF;
uint vIdx1 = (packed >> 8) & 0xFF;
uint vIdx2 = (packed >> 16) & 0xFF;
triangles[gtid] = uint3(vIdx0, vIdx1, vIdx2);
}
if (gtid < m.VertexCount) {
uint vertexIndex = m.VertexOffset + gtid;
vertexIndex = VertexIndices[vertexIndex];
float4x4 MVP = mul(Scene.CameraVP, Instances[instanceIndex].M);
vertices[gtid].Position = mul(MVP, float4(Vertices[vertexIndex].Position, 1.0));
float3 color = float3(
float(meshletIndex & 1),
float(meshletIndex & 3) / 4,
float(meshletIndex & 7) / 8);
vertices[gtid].Color = color;
}
}
MSL for Metal
struct Payload {
uint InstanceIndices[AS_GROUP_SIZE];
uint MeshletIndices[AS_GROUP_SIZE];
};
using MeshOutput = metal::mesh<MeshVertex, void, 128, 256, topology::triangle>;
[[mesh]]
void meshMain(
constant SceneProperties& Scene [[buffer(0)]],
device const Vertex* Vertices [[buffer(1)]],
device const Meshlet* Meshlets [[buffer(2)]],
device const uint* MeshletVertexIndices [[buffer(3)]],
device const uint* MeshletTriangeIndices [[buffer(4)]],
device const Instance* Instances [[buffer(5)]],
object_data const Payload& payload [[payload]],
uint gtid [[thread_position_in_threadgroup]],
uint gid [[threadgroup_position_in_grid]],
MeshOutput outMesh)
{
uint instanceIndex = payload.InstanceIndices[gid];
uint meshletIndex = payload.MeshletIndices[gid];
device const Meshlet& m = Meshlets[meshletIndex];
outMesh.set_primitive_count(m.TriangleCount);
if (gtid < m.TriangleCount) {
//
// meshopt stores the triangle offset in bytes since it stores the
// triangle indices as 3 consecutive bytes.
//
// Since we repacked those 3 bytes to a 32-bit uint, our offset is now
// aligned to 4 and we can easily grab it as a uint without any
// additional offset math.
//
uint packed = MeshletTriangeIndices[m.TriangleOffset + gtid];
uint vIdx0 = (packed >> 0) & 0xFF;
uint vIdx1 = (packed >> 8) & 0xFF;
uint vIdx2 = (packed >> 16) & 0xFF;
uint triIdx = 3 * gtid;
outMesh.set_index(triIdx + 0, vIdx0);
outMesh.set_index(triIdx + 1, vIdx1);
outMesh.set_index(triIdx + 2, vIdx2);
}
if (gtid < m.VertexCount) {
uint vertexIndex = m.VertexOffset + gtid;
vertexIndex = MeshletVertexIndices[vertexIndex];
float4x4 MVP = Scene.CameraVP * Instances[instanceIndex].M;
MeshVertex vtx;
vtx.PositionCS = MVP * float4(Vertices[vertexIndex].Position, 1.0);
vtx.Color = float3(
float(meshletIndex & 1),
float(meshletIndex & 3) / 4,
float(meshletIndex & 7) / 8);
outMesh.set_vertex(gtid, vtx);
}
}
Notable Changes
SceneProperties replaced CameraProperties
struct SceneProperties {
float4x4 CameraVP;
uint InstanceCount;
uint MeshletCount;
};
// -----------------------------------------------------------------------------
// HLSL
// -----------------------------------------------------------------------------
DEFINE_AS_PUSH_CONSTANT
ConstantBuffer<SceneProperties> Scene : register(b0);
// -----------------------------------------------------------------------------
// MSL
// -----------------------------------------------------------------------------
constant SceneProperties& Scene [[buffer(0)]]
This change is identical to the same change in the amplification shader.
Instance Transform Matrices (aka Instance Model Matrices)
struct Instance
{
float4x4 M;
};
// -----------------------------------------------------------------------------
// HLSL
// -----------------------------------------------------------------------------
StructuredBuffer<Instance> Instances : register(t5);
// -----------------------------------------------------------------------------
// MSL
// -----------------------------------------------------------------------------
device const Instance* Instances [[buffer(5)]]
Shader resource for Instances buffer. Again, this buffer just stores a single model matrix for our each of our instances. We use it a few lines down as part of the MVP matrix calculation.
Instance and Meshlet Index via Payload
uint instanceIndex = payload.InstanceIndices[gid];
uint meshletIndex = payload.MeshletIndices[gid];
We now have instanceIndex from the payload in addition to the meshletIndex.
Instance Transform Matrix Lookup
float4x4 MVP = Scene.CameraVP * Instances[instanceIndex].M;
MeshVertex vtx;
vtx.PositionCS = MVP * float4(Vertices[vertexIndex].Position, 1.0);
Here we use instanceIndex to find index into the Instances array to get the model matrix. The math is reworked a bit to calculate a MVP matrix from the instance’s model matrix and the Scene.CameraVP. The Metal shader code is shown here for brevity. The only diffence between the HLSL and MSL code is the usage of mul() in the HLSL code. I trust you can work that out.
Full Shader Source
Here are links to the HLSL and MSL:
Rendered Image
The 113_mesh_shader_instancing sample renders 200 instances of the horse statue.